Your agent now builds a model team, not just a model
JITM.ai Pro now trains four model families in parallel and learns how to combine them into a single prediction endpoint. Connect any MCP-compatible LLM, hand it a CSV, and let it build the model team for you.
Pro just got a prediction upgrade with teeth. Train a model now and we don't put all our chips on one algorithm. We hire a small team of specialists, watch how each one behaves on your data, and figure out the right way to combine their judgement into one prediction endpoint.
Crucially, you don't need to know any of this to use it. Connect Claude, ChatGPT, Cursor, or any MCP-compatible client, point it at your CSV, and ask it to build you a model. The LLM handles the rest: uploading the data, scanning the columns, picking the target, kicking off training, reading the results, and calling the prediction endpoint at the end.
Why a model team beats a single model
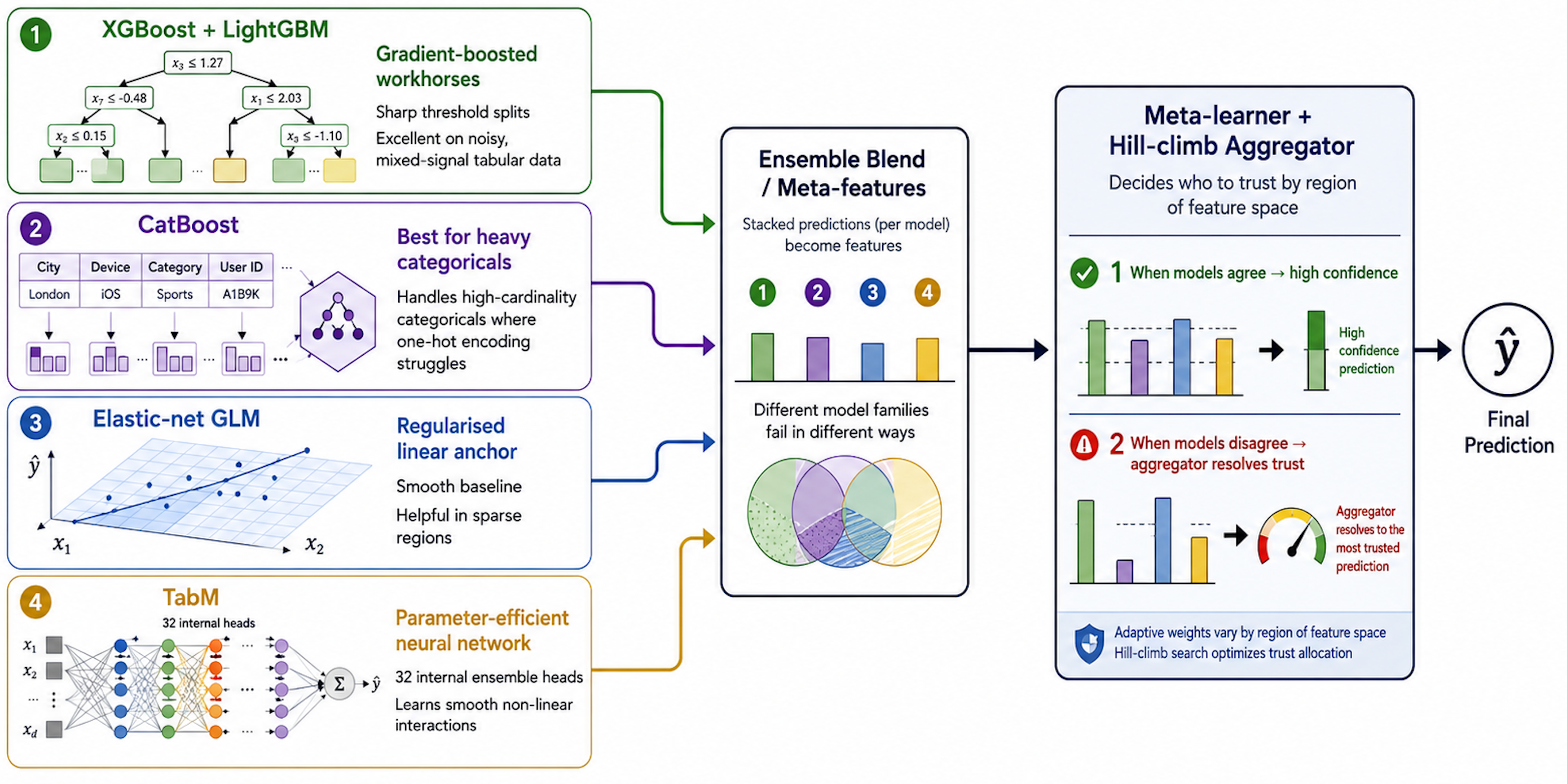
Every model family sees the world through its own lens. Boosted trees love sharp rules and crisp interactions. Linear models love smooth gradients. Neural nets love subtle multi-column patterns the others would shrug at. Any single algorithm can be brilliant and still have blind spots; a team gets to triangulate. When all four agree, the prediction is confident. When they disagree, the aggregator picks who to trust on this region of the feature space.
Meet the team
XGBoost and LightGBM are the workhorses: fast, opinionated gradient-boosted trees that win most tabular Kaggle competitions and earn their keep on almost any dataset. GLM is the steady hand: a regularised linear model that won't impress you with creativity, but quietly stops the boosters doing something stupid in the sparse corners of your data. TabM is the new hire from Yandex Research: a parameter-efficient neural network with 32 internal ensemble heads, brought in to spot the smooth non-linear interactions the trees can only fake with step functions. CatBoost waits on the bench and gets called up when your dataset is heavy on high-cardinality categoricals, where its ordered target encoding does things the others can't.
The final blend matters
Naive ensembles average every model equally and hope for the best. That works, sort of, the way that picking a restaurant by averaging the team's votes works. We do something smarter. Three aggregators compete to combine the predictions: a weighted blend that scores each family on out-of-fold performance, a stacked meta-learner that learns the optimal mix, and a Caruana-style hill-climber that greedily picks the combination that minimises validation loss. Whichever wins on your data is the one that gets deployed.
MCP is what makes this immediately usable
Here's the part that makes the new stack practical. Paste https://mcp.jitm.ai into your MCP client of choice, sign in, and your LLM gets the full machine-learning loop as a set of tools it can call. Uploading data, scanning columns, picking targets, training, monitoring, explaining, predicting. It doesn't need to know how to tune XGBoost or when to reach for a GLM. Behind every tool call is a serious ML pipeline; the LLM only has to know what you want next.
For builders, not just ML teams
This is for people who know their data and their product, but don't want to spend a month standing up an ML platform to test a hunch. Maybe you suspect your churn signal lives in the gap between sign-up and first feature use. Maybe your support team thinks they can predict which tickets will escalate from the wording of the first message. Maybe your ops team is curious whether yesterday's weather predicts today's no-shows. Upload the CSV, ask your LLM to build the model, and you'll know in a few minutes whether the hunch is worth chasing. The agent stays in the workflow where the question started.
For ML practitioners
Under the hood, Phase 2 runs all four families in parallel through Optuna TPE search on family-tuned grids, with shared CV splits so the out-of-fold predictions align cleanly for stacking. Three aggregators (weighted blend, stacked meta-learner, Caruana hill-climb) compete on OOF log-loss or RMSE; the winner ships to the inference endpoint. Phase 2 trains on the full dataset with no sampling, so the deployed model is the one that has actually seen everything.
A small trick that makes the linear and neural anchors actually competitive
Linear models can't natively express 'feature > threshold.' Neural networks can, but they pay a sample-efficiency tax to learn it. So before training the non-tree families, we fit a shallow decision tree on the data and hand its split rules to GLM and TabM as extra binary features. They get the boosters' favourite trick (sharp threshold-based features) as a free input, then add their own perspective on top. The tree models don't get these features; they'd just be relearning their own work. The pattern goes back to Facebook's 2014 GBDT-LR paper, well-known in ad-tech and not commonly seen in general-purpose AutoML.
What you should do
Find a CSV you already know well. Hand it to your LLM over MCP. Ask it to build you a model and explain what came out. The end product looks the same as before: one prediction endpoint, one URL, one JSON request. The only thing that's changed is the bench depth behind it.