Three expert algorithms, time-aware splits: Phase 2 gets smarter
Every Phase 2 model on higher tiers now draws from three different learning algorithms and combines the best from each. And when your data has a time dimension, JITM.ai now respects it automatically, so models don't learn by peeking at the future.
Two of the quieter, deeper upgrades we've shipped this week change results in a very practical way. Your models will usually be more accurate, and they'll be more honest about how accurate they actually are on future data. Here's what changed and why it matters.
Three model families, one best answer
For Pro and Enterprise tiers, JITM.ai now trains three different families of gradient-boosted tree models side by side: XGBoost, LightGBM, and CatBoost. Think of these as three expert mathematicians who solve the same problem in slightly different ways. Each has strengths on certain shapes of data: XGBoost is the classic workhorse, LightGBM is unusually fast on wide tables with lots of columns, and CatBoost handles messy categorical fields (things like "city" or "product_category") with less fuss. Instead of betting everything on one algorithm, JITM.ai runs all three through its own hyperparameter search and combines the best from each into an ensemble. The final prediction is a soft vote: each family casts a probability, and those votes are averaged. In practice, that averaging smooths out the weirdness where one family happens to overfit a particular corner of the data.
You can see which family is pulling the weight
The model detail page now gives each family its own colour (XGBoost green, LightGBM gold, CatBoost purple). Every fold card is tagged with the family that produced it, the per-family breakdown panel shows how each one performed, and the live training console tags trials so you can watch each family's search evolve in real time. The common pattern is that one family wins most folds, one or two others win occasional folds, and the ensemble average beats all of them.
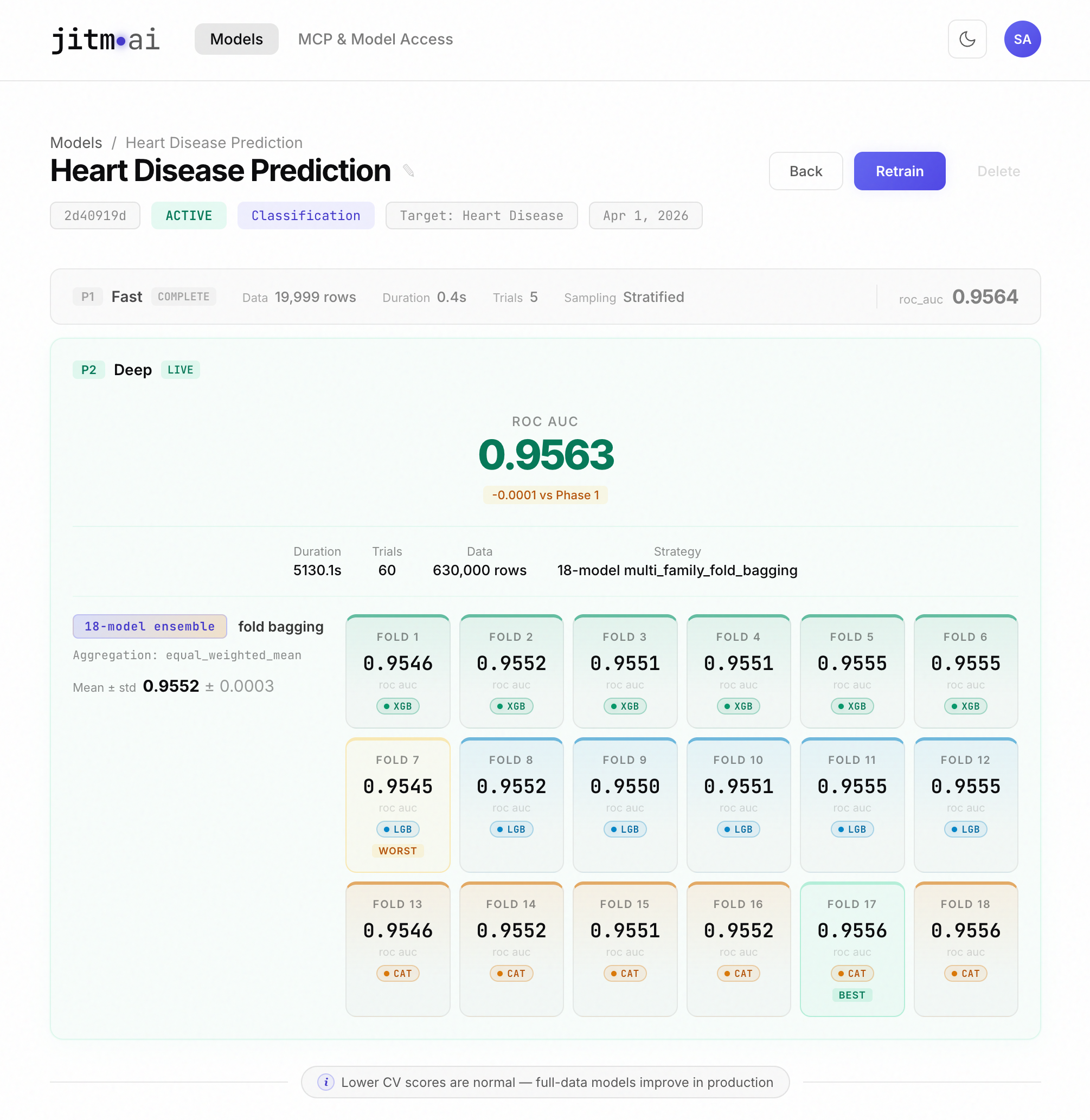
Phase 2 cross-validation, not just a holdout
Previously, Phase 2 evaluated models on a single held-out slice of data. That's a fine first signal, but it can be lucky or unlucky depending on which rows happen to land in the holdout. Phase 2 now uses k-fold cross-validation on higher tiers. We split your training data into folds (5 for Pro, 6 for Enterprise), train a model on all folds except one, and evaluate on the one left out. We rotate through every fold, which gives K independent estimates of real-world performance instead of one. The reported metric is the average, and every fold model is kept and combined at inference time. This is where "fold bagging" comes from: each fold produces a slightly different model, and averaging their predictions tends to be more robust than any single one.
For ML practitioners: what we actually do
We use stratified k-fold for classification (every fold carries the same class balance) and plain k-fold for regression. When a grouping column is present (sessions, users, races), we switch to GroupKFold so the same group never appears in both train and validation. When a datetime axis is detected, we switch to TimeSeriesSplit. All of this is selected automatically from the dataset rather than asked of the user.
Time-aware splits for time-aware data
Cross-validation is a problem when your data has a time order. If your dataset is daily sales, sensor readings, or races across a season, randomly shuffling rows into folds lets a model cheat: it sees the future during training and looks brilliant on the holdout, then fails in production. This is the single most common silent bug in real-world ML. JITM.ai now detects a time column automatically. When it finds one, validation switches to chronological mode: the holdout is always the most recent slice of data, and cross-validation uses forward-only folds so each fold trains on everything before a cutoff and validates on the slice that comes right after. The model never sees any row more recent than what it's predicting.
Smarter datetime features on time-series data
We also trimmed what the feature engineer extracts from the time column itself on these datasets. Parts like "year" or a day-of-month index that keeps trending across the series create artificial distribution shifts between train and validation (the training period has dates the validation period can never see), so those get dropped on the detected time axis. Seasonal, cyclic parts (month, day-of-week, hour, is-weekend) stay, because they repeat and generalise. On top of that, our leakage detection still runs: if training metrics are dramatically better than validation, we flag it as likely leakage (future-into-past, target-derived features, or ID leakage) without blocking the run.
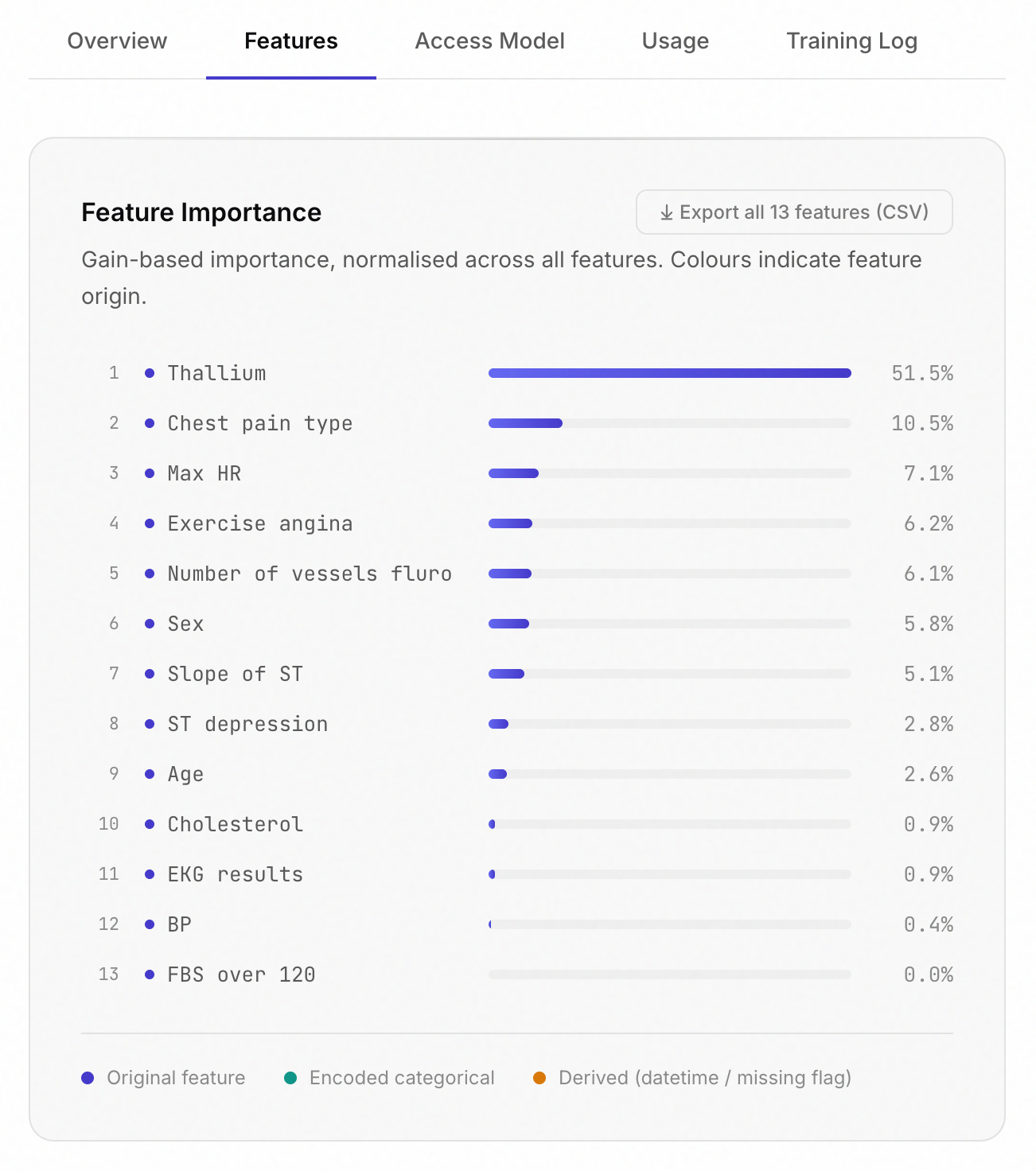
What you should do
Nothing. If your data has a time dimension, JITM.ai will notice. If you're on Pro or Enterprise, you're getting three-family ensembles and k-fold validation by default. Builder tier still gets Phase 2 with time-aware holdout and the same leakage checks, with XGBoost as the sole family. Free tier sees Phase 1 results only. The improvements apply to every new model you train from now, and existing models keep serving predictions from their original training until you retrain them.